So I was bored and I set up an XMPP server under
👆️.op-co.de, in addition to the one I already had under
ツ.op-co.de. It worked with some clients and failed with
others. But both ツ and 👆️ are valid Unicode 1.1 characters, so WTF?
Buckle up (or better: put on your 🤿) for the 19-RFC deep dive...
...or skip right to the TL;DR.
Note: despite my generous use of Emojis throughout this post, none of it was
generated by a text extruder machine. All words are the product of
artisanal typing on my keyboard, and the Emojis were hand-selected from an
Emoji-picker widget.
XMPP addresses
XMPP, the eXtensible Messaging and Presence Protocol,
formerly known as Jabber®, defines its address format in
RFC 7622.
An XMPP address (formerly known as Jabber® ID, or JID, as used in the RFC) has three parts:
jid = [ localpart "@" ] domainpart [ "/" resourcepart ]
The localpart is usually the username, but is not used when addressing a server.
The domainpart is the hostname or domain name, and can be a Unicode DNS
identifier, an IPv6 address in square brackets, or a legacy IP address. This
is the only mandatory part of a JID.
The resourcepart is the internal identifier of an individual client,
allowing a user to have multiple clients connected at the same time; it is
also used for the nickname in
XEP-0045: Multi-User Chat.
Each of these three parts must be valid UTF-8 and can be up to 1023 bytes (not
characters!) in length.
Furthermore, there are restrictions for each part, for example:
localpart = 1*1023(userbyte)
a "userbyte" is a byte used to represent a UTF-8 encoded Unicode code point
that can be contained in a string that conforms to the UsernameCaseMapped
profile of the PRECIS IdentifierClass defined in RFC 7613
[...]
Come again, please? Okay, let's take this apart, slowly.
a "userbyte" is a byte used to represent a
UTF-8 encoded Unicode code point
This is a convoluted way to say that we accept up to 1023 bytes (not
characters!) of valid UTF-8.
that can be contained in a string that conforms to the UsernameCaseMapped
profile of the PRECIS IdentifierClass defined in RFC 7613
In addition to being valid UTF-8, it must also conform to the
IdentifierClass in PRECIS (RFC 7613).
PRECIS: Preparation, Enforcement, and Comparison of Internationalized Strings
PRECIS is the successor to Stringprep
(RFC 3454, which we can
ignore for now).
However, the PRECIS definition in RFC 7613 is obsoleted by RFC
8265, which we can't ignore and will have to take our character
profiles and classes from.
So we need the IdentifierClass for the localpart, and furthermore
the FreeformClass for the resourcepart.
PRECIS classes, profiles and categories
The earlier Stringprep approach explicitly defined its classes as valid ranges
of Unicode code points (characters). However, given that Unicode is a living
(versioned) standard, new characters (and new Emojis! 💡) get added every
year. This left Stringprep in an uncomfortable place, forever hard-coded to
the long-superseded 2002
Unicode 3.2 standard.
To allow for future compatibility, PRECIS took a different path. It
describes an algorithm that can be applied to an individual Unicode
character in order to determine whether it belongs to a certain PRECIS
class.
The classes (IdentifierClass and FreeformClass) are defined in
RFC 8264, and the profiles (UsernameCasePreserved,
UsernameCaseMapped, OpaqueString, Stringprep) are defined in
RFC 8265.
Furthermore, PRECIS attempts to retain backward compatibility with earlier
standards like IDNA2008, as well as with itself. If a certain character is
"valid" under an earlier version of Unicode, PRECIS tries to ensure that it
stays "valid" under later versions. The only explicit exception from this is
that code points that were "undefined" in earlier Unicode versions can later
be assigned and move to "valid" or "disallowed".
Each of these rules is applied to individual characters, or to character
categories, as defined in RFC 5892: IDNA code points.
Given this toolset, we can now get back to the individual XMPP address parts.
XMPP address elements
localpart - the user name
As stated in RFC 7622 above, the localpart must be...
a string that conforms to the UsernameCaseMapped profile of the PRECIS
IdentifierClass
So we have the profile (UsernameCaseMapped) and the class
(IdentifierClass) to look up.
The UsernameCaseMapped transformation
The UsernameCaseMapped profile in RFC 8265 performs some
normalization steps: it requires
decomposition of certain East Asian
characters, lowercasing, Unicode Normalization Form C, and application of the
Bidi rule.
Later, RFC 8265 § 3.3.2 says:
Ensure that the string consists only of Unicode code points that are
explicitly allowed by the PRECIS IdentifierClass defined in
Section 4.2 of [RFC8264].
What's allowed by IdentifierClass?
RFC 8264 §4.2.1
defines the valid and disallowed character properties, as well as certain
groups that require special treatment.
Valid identifiers contain "Code points traditionally used as letters and
numbers in writing systems", the ASCII 7-bit characters U+0021 through U+007E,
and a few characters that are only allowed in a certain context, like U+00B7
MIDDLE DOT which is only allowed inside the Catalan
ela geminada "ŀl".
The ツ character (U+30C4 KATAKANA LETTER TU) belongs to the "Letter, other" (Lo)
category of Unicode)
and thus is a valid letter character allowed in IdentifierClass. The 👆️
emoji (U+261D WHITE UP POINTING INDEX) belongs to the "Symbol, other" (So)
category with all the other Emojis. The whole "Symbol" category is disallowed
inside of IdentifierClass. Bummer. Sad trombone! 🎶
On the other hand, the "Nonspacing Mark" (Mn) category is allowed, and so
ḩ̸̡͇͉̬̓͝e̷͙̪̯̬̬͍͒̂̓̽̀̄ ̵̨̨̪̯̞̠͒̐͘͝c̷͍͆o̸̡̢̥͌̒̌̀͜͜m̶̬̙̙̓̌͘͠ë̷́̉́͜t̴̍̔͜͠h̷̖̭̫̥̖̥͐͂͊͒̓.
Putting localpart together
So essentially, PRECIS only allows the boring regular lowercase letters from
any supported language, and none of the fun Emojis.
To add insult to injury,
RFC 7622 §3.3.1 imposes
further restrictions by disallowing some more fun characters:
" U+0022 (QUOTATION MARK)
& U+0026 (AMPERSAND)
' U+0027 (APOSTROPHE)
/ U+002F (SOLIDUS)
: U+003A (COLON)
< U+003C (LESS-THAN SIGN)
> U+003E (GREATER-THAN SIGN)
@ U+0040 (COMMERCIAL AT)
However, there are still a bunch of "funny" permitted characters left from the
ASCII7 block:
!#$%()*+;=?[\]^`{|}
This leaves us with some valid old-school ASCII smiley user name options on the table:
;=)
B*}
And a bunch of Unicode letters that can be abused, with special thanks to
Egyptian hieroglyphs:
| Symbol |
Code Point |
Name |
| ۃ |
U+06C3 |
ARABIC LETTER TEH MARBUTA GOAL |
| ツ |
U+30C4 |
KATAKANA LETTER TU |
| 𓀐 |
U+13010 |
EGYPTIAN HIEROGLYPH MAN WITH BLEEDING HEAD WOUND |
| 𓂸 |
U+130B8 |
EGYPTIAN HIEROGLYPH HUMAN PHALLUS |
| 𓂹 |
U+130B9 |
EGYPTIAN HIEROGLYPH ERECTILE DYSFUNCTION |
| 𓃂 |
U+130C2 |
EGYPTIAN HIEROGLYPH LEG SEVERED BY HAND GRENADE |
| 𓄀 |
U+13100 |
EGYPTIAN HIEROGLYPH ENRAGED YAXIM USER |
| 𓀬 |
U+1302C |
EGYPTIAN HIEROGLYPH CHUCK NORRIS RIDING ON TWO GIRAFFES |
The domain part
Back to RFC 7622 §3.1:
domainpart = IP-literal / IPv4address / ifqdn
the "IPv4address" and "IP-literal" rules are
defined in RFCs 3986
and 6874, respectively,
and the first-match-wins (a.k.a. "greedy") algorithm described in
Appendix B of RFC 3986
applies to the matching process
We will leave IP literals out... for now. Just a note that the format for IPv6
literals need to be enclosed in brackets and may contain a %zone postfix.
ifqdn = 1*1023(domainbyte)
a "domainbyte" is a byte used to represent a UTF-8 encoded Unicode code
point that can be contained in a string that conforms to
RFC 5890
RFC 5890: IDNA Definitions and Document Framework is a new addition
to our list. It is the "Definitions" part of the IDNA2008 ("Internationalized
Domain Names for Applications", released in 2008) specification. The
RFC 5892 we encountered earlier belongs to the same specification
suite.
However, there is not a single "string" that "conforms" to RFC 5890.
RFC 7622 §3.2.1
has a more precise requirement:
the string consists only of Unicode code points that are allowed in NR-LDH
labels or U-labels as defined in RFC5890.
An NR-LDH (non-reserved letter, digit, hyphen) label is an ASCII label (not
containing "special" Unicode characters) according to the "hostname"
syntax defined in
RFC 952 back in 1982.
IDNA-valid U-labels
The U-label definition can be found in
RFC 5890 §2.3.2.1:
[A U-label] is also subject to the constraints about permitted characters that are
specified in Section 4.2 of the Protocol document and the rules in the
Sections 2 and 3 of the Tables document [...].
Rant about RFC rendering
The links in the quoted paragraph are pointing to the wrong RFC, so I disarmed
them in the quote above.
The normative RFC format before RFC 8650 (late 2019) was fixed-width ASCII,
58 lines, 72 characters
with manual page breaks, designed to be printed by a 1982 line printer on US
Legal (even though the PDF renderings are using US Letter). The markup in the
HTML versions linked from this post is auto-generated from a semantic analysis
of the normative ASCII documents.
The fixed-width fixed-page format is unreadable on mobile devices, and
effectively trips up reflow algorithms. There used to be an
alternative ebook rendering of RFCs
that was the only useful way for people with bad eyes to read RFCs. It
stopped rendering new documents in 2019
and was abandoned in 2022. Nobody cared.
The links above point to sections of RFC 5890, because the string parser saw
"Section x.y.z" and assumed it to be a reference to section x.y.z of the
current RFC. It was not. The links should go to
RFC 5891 §4.2,
RFC 5892 §2 and
§3.
U-label definition
Let's get back to the U-label definition from
RFC 5890 §2.3.2.1.
It is a variant of the "IDNA-valid string":
For IDNA-aware applications, the three types of valid labels are "A-labels",
"U-labels", and "NR-LDH labels" [...]
A string is "IDNA-valid" if it meets all of the requirements of these
specifications for an IDNA label. [...]
[A U-label] is also subject to the constraints about permitted characters that are
specified in Section 4.2 of the Protocol document and the rules in the
Sections 2 and 3 of the Tables document [...].
So. Uhm. A U-label needs to be IDNA-valid, and an IDNA-valid string is either
a U-label, an A-label or an NR-LDH label. This is not a recursive definition!
The referenced
RFC 5891 §4.2 Permitted Character and Label Validation
further clarifies:
The candidate Unicode string MUST NOT contain characters that appear in the
"DISALLOWED" and "UNASSIGNED" lists specified in the Tables document.
Furthermore, it may not begin or end with a "-", and must not contain a "--"
at the third position, in order to not be mixed up with A-labels.
An U-label can be up to 252 bytes (not characters!)
long (§4.2), but
its ASCII-compatible encoding (ACE / A-label) form must not exceed 63 ASCII
characters (equal to bytes!). In addition, DNS limits the full hostname to 255
characters.
Valid U-label characters
The set of valid characters is defined by RFC 5892 §2.
A minor detail that we omitted above, when talking about valid localpart
characters, was that RFC 8264 in fact does not define the
character categories, but instead contains references to the respective
subsections of RFC 5892 §2.
Despite of that, the valid character sets for localpart and domainpart are
not equal. ß U+00DF LATIN SMALL LETTER SHARP S is explicitly included for
U-labels (I haven't figured out why it would be disallowed though), as is 〇
U+3007 IDEOGRAPHIC NUMBER ZERO (Nl) (which is in the disallowed "Letter
Number" (Nl) category) and there is a number of other
exceptions.
Korean is restricted to
modern Hangul syllable characters.
IDNA is using
case folding
to normalize the letter case. This matches the lowercase conversion of
RFC 8265, except
when it doesn't.
Furthermore, DNS Registries are allowed to restrict the valid characters for
domain names, probably in order to limit
homoglyph attacks.
Putting domainpart together
There is a significant overlap between localpart and domainpart. However,
- U+002D HYPHEN-MINUS is the only special character from the ASCII set
that's still allowed, and it may not appear in all positions.
Lowercase letters (or uppercase Cherokee) and numbers are allowed, ASCII
smileys are not. Egyptian hieroglyphs and diacritics are still in the game for
subdomains, or if your Registry allows them on the domain name.
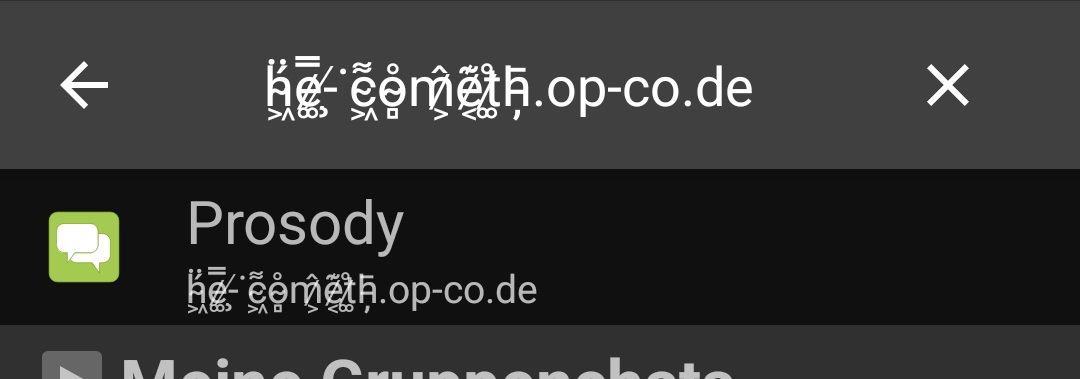
To prove a point, this post is reachable via
ḧ̴͖́e̷͚̿-̸̧͘c̴͖͌o̴̻̊m̷͕̂e̷͔͊t̷͚̊h̵̦̄.op-co.de and there is an XMPP server,
too:
The resource part (a.k.a. chatroom nickname)
RFC 7622 §3.4 is
where the resourcepart gets defined:
The resourcepart of a JID is an instance of the OpaqueString profile of the
PRECIS FreeformClass, which is specified in RFC7613.
This is actually the same mechanism as with localpart, just with a different
profile and a different class.
Characters in FreeformClass
RFC 8264 §4.3.1
defines the valid FreeformClass code points. This includes all traditional
letters and numbers, printable ASCII (U+0021 through U+007E), punctuation,
spaces, and 🚨 symbols‼️ 🤯 Finally!
On top, OpaqueString will apply
some normalization,
including the conversion of all non-ASCII whitespace into U+0020. Character
case will be retained.
Stripping nicknames
RFC 7622 §3.4.1
also has a note regarding the use of resourcepart for nicknames:
In some contexts, it might be appropriate to apply more restrictive rules to
the preparation, enforcement, and comparison of XMPP resourceparts. For
example, in XMPP Multi-User Chat [XEP-0045] it might be appropriate to apply
the rules specified in [PRECIS-Nickname].
"it might be appropriate" is not normative language, right? The Nickname
profile is derived from FreeformClass and is a mapping that removes leading
and trailing whitespace, and reduces consecutive whitespace into one U+0020.
And it applies the lowercase transformation for nickname comparisons, to
disallow multiple users to have the same case-normalized nickname.
That's it.
So you can have all the Emojis as your nickname, right? RIGHT?
Hysterical raisins
Jabber was born in 1999.
The first formal XMPP specification was RFC 3920 in 2004.
Over the decades, both the XMPP specification and the Unicode standard evolved, thus also changing what
is considered a valid XMPP address. Implementations that we need to
interoperate with might be running on some older version of the specification,
and accept a different subset of "valid" Unicode characters.
Let's sort this out as well!
2004: The Original Specification
RFC 3920 §3 Addressing Scheme
defines the JID syntax:
- A "domain identifier" (later renamed to
domainpart) is an IDNA
string according to RFC 3490 (IDNA2003) and must match the
Nameprep profile defined in RFC 3491.
- A "node identifier" (
localpart) must match the Nodeprep profile defined
in Appendix A.
- A "resource identifier" (
resourcepart) must match the Resourceprep
profile from
Appendix B.
Nameprep, Nodeprep and Resourceprep are profiles of Stringprep (from
RFC 3454, which contains
tables with allowed and prohibited characters, as well as character mappings
to perform, based on Unicode 3.2).
Each of the profiles defines the set of tables and steps to apply. For
example, the Nameprep processing consists of three steps:
- Mapping:
- remove ("map to nothing") 27 different hyphenation characters
- apply case mapping and folding to 1676 characters ("A" ➡️"a", "𝛬" ➡️"λ", ...)
- Prohibited Output (based on tables in
RFC 3454 Appendix C):
- disallow ASCII and non-ASCII space characters (but not control
characters - those are disallowed by
XML 1.0,
which is the mandatory foundation of XMPP)
- disallow Private Use and "non-character" ranges from Unicode, as well as
surrogate codes
- disallow some inappropriate characters (like
� U+FFFD REPLACEMENT
CHARACTER) and orientation markers
- Only allow unassigned code points according to IDNA rules (allowed in
queries, not in "stored strings")
The handling of IPv6 literals in RFC3920 assumes that they are inserted
verbatim, with no surrounding [] and no %zone identifier.
Nodeprep is similar to Nameprep, but disallows control characters, as well
as the forbidden characters we know from localpart, namely "&'/:<>@
Resourceprep is also similar to Nameprep but allows ASCII whitespace and
doesn't perform case folding, allowing for uppercase characters.
But on the good side, neither IDNA2003 nor the Stringprep profiles disallow
the use of Emojis (that are part of Unicode 3.2) in domain names! 🎉
2008: A New IDNA Hope
However, the experience of operating IDNA2003 in the wild for a few years
led to the documentation of 37 pages (measured in 72-character ASCII on US
Legal) of issues and shortcomings, documented in
RFC 4690 and including this
section:
5.1.1. Elimination of All Non-Language Characters
Unicode characters that are not needed to write words or numbers in any of
the world's languages should be eliminated from the list of characters that
are appropriate in DNS labels. In addition to such characters as those used
for box-drawing and sentence punctuation, this should exclude punctuation
for word structure and other delimiters. While DNS labels may conveniently
be used to express words in many circumstances, the goal is not to express
words (or sentences or phrases), but to permit the creation of unambiguous
labels with good mnemonic value.
I guess that Emojis lack good mnemonic value. RIP. 🪦
The result of this analysis was the replacement of IDNA2003 with
IDNA2008 in... you guessed it... 2010! To be fair, the IDNA2008
suite was "largely completed in 2008", and got submitted to the IETF in
October 2008.
The IDNA2008 RFC collection obsoleted the previous RFCs, and thus the stricter
domainpart requirements (no Emojis) were automatically turned into law in
2010, without having to change any of the XMPP specifications.
But we can still have Emojis in usernames and nicknames, right? 🥹
2010 Revenge of the PRECIS
The update to IDNA made Stringprep obsolete, and prompted the creation of the
Preparation and Comparison of Internationalized Strings Working Group
at the IETF.
While the WG was working on the PRECIS specifications, the XMPP core
specifications got a major overhaul in 2011. As part of that, the address
format was updated and separated into its own document,
RFC 6122:
Because all other aspects of revised documentation for XMPP have been
incorporated into [XMPP], the XMPP Working Group decided to temporarily
split the XMPP address format into a separate document so as not to
significantly delay publication of improved documentation for XMPP. It is
expected that this document will be obsoleted as soon as work on a new
approach to preparation and comparison of internationalized addresses has
been completed.
The updated address format still relied on IDNA2003, but developers were
encouraged to look at IDNA2008.
RFC 6122 furthermore introduced the localpart, domainpart and
resourcepart names and changed IPv6 literals to use the bracketed
IP-literal syntax from RFC 3986.
2015 The Next Generation
As announced in the intro of RFC 6122, it was soon replaced by
RFC 7622, which we might vaguely remember from the beginning of
this post. It was published in 2015, based on the still fresh RFC
7613 PRECIS specification.
The PRECIS suite and the updated XMPP address format introduced case folding,
replaced the Stringprep profiles with the PRECIS classes, profiles and
categories explained above, and effectively disallowed Emojis in the
localpart and domainpart of XMPP addresses (following the IDNA2008
insights).
As mentioned before, RFC 7613 was obsoleted by RFC 8265,
which corrected a few things and went from case folding to lowercase
again. 🤷
This happened in 2017 and, together with RFC 8266 (Nicknames) is
the end of the evolution of the RFCs needed to understand XMPP addresses.
So you just told me that Emojis in nicknames are still allowed, yes?
XMPP address validation in the wild
The IETF is about "rough consensus and running code". We've seen the
consensus and how it changed over two decades, but in the end it's the running
code that will say "no" when you try to butt dial an XMPP address.
Consensus in distributed systems
Something that you enter might go through up to five different hops (and
different XMPP implementations; I'm omitting protocol bridges, but the point
should be clear):
- Your own client, which is responsible for sanitizing (or refusing) your
input, through its user interface or config file.
- Your server, receiving your input through a client-to-server connection.
- Optionally, a XEP-0045 Multi-User Chat (MUC) room where you are
an occupant, through a server-to-server connection.
- The recipient's server, through a server-to-server connection shared with
other users.
- The recipient's client, through its own connection to its server.
Your client is the easiest part, as it can simply reject forwarding something
it disagrees with. If the "Add contact" button is greyed out, you've arrived
at a dead-end. ⛔
The following hops on the path can't grey out the button if they consider your
XMPP address, coming through an XML stream, as invalid. According to RFC 6120,
they have to treat it as a (recoverable) stanza-related error, and reject the
respective XML stanza (and not terminate the XML stream):
8.3.3.8. jid-malformed
The sending entity has provided (e.g., during resource binding) or
communicated (e.g., in the 'to' address of a stanza) an XMPP address or
aspect thereof that violates the rules defined in [XMPP‑ADDR];
the associated error type SHOULD be "modify".
So if a recipient disagrees about the PRECIS / IDNA version with your client
or your server, it will reject the respective stanza before it can be
processed.
Robot Face vs. the MUC Occupants
When joining a MUC, you send a presence stanza to your occupant address,
constructed by appending your nickname as the resourcepart to the room
address. If you choose an evil Emoji nickname and the room rejects it, it will
send an error response, and you won't be able to join the room.
Now if the room does accept your nickname, it will forward the presence,
sending it from your occupant address, to all other occupants.
I first ran into this issue, not knowing much about IDNA, PRECIS or
Stringprep, back in 2017:
11:28:50 ---> 🤖 joined the room
11:28:50 <--- T....s has left the room (Kicked: jid malformed: The source address
is invalid: prosody@conference.prosody.im/🤖)
11:28:51 <--- N..........s has left the room (Kicked: jid malformed)
11:28:51 <--- d......n has left the room (Kicked: jid malformed: The source address
is invalid: prosody@conference.prosody.im/🤖)
11:28:51 <--- d.......o has left the room (Kicked: jid malformed: The source address
is invalid: prosody@conference.prosody.im/🤖)
11:28:51 <--- a..v has left the room (Disconnected: not-well-formed)
11:29:08 ---> a..v joined the room
11:32:18 ---> T....s joined the room
11:32:18 <--- T....s has left the room (Kicked: jid malformed: The source address
is invalid: prosody@conference.prosody.im/🤖)
Any downstream server or client that does not accept this occupant presence
will send a stanza error back to the MUC. The MUC will treat that error as a
non-recoverable session error and remove the respective occupants.
As long as you stay in the room, the other clients will repeatedly reconnect,
receive your presence, and get kicked out. If you send a message to the room,
it will get pushed to joining clients as part of the room history even after
you leave.
Today, the situation is only slightly different:
00:14:39 ---> 🤖 joined the room
00:14:39 <--- H....r (....) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- c...........s (Monocles) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- p......d (Conversations) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- E..a (Cheogram) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- m.....x (Conversations) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- y..h (Conversations) has left the room due to an error
(Kicked: bad request)
00:14:39 <--- b.....a (.../Conversations....) has left the room due to an error
(Kicked: bad request)
Most of the affected users seem to be running
Conversations or its forks Cheogram and Monocles,
and the clients(?) responded to the presence with a "bad-request" error.
In addition to that issue, ejabberd sends the error response over the wrong
half of the server-to-server stream, so:
Jul 12 01:19:36 s2sout5e57d6de9d50 debug Received[s2sout]: <presence to='test@chat.yax.im/🤖' type='error' id='noLNT-110871' from='georg@conversations.im/Conversations.jxm9v159lx' xml:lang='de-DE'>
Jul 12 01:19:36 stanzarouter warn Received a stanza claiming to be from conversations.im, over a stream authed for chat.yax.im!
Jul 12 01:19:36 s2sout5e57d6de9d50 debug Disconnecting chat.yax.im->conversations.im[s2sout], <stream:error> is: <stream:error><not-authorized xmlns='urn:ietf:params:xml:ns:xmpp-streams'/></stream:error>
Looking at implementations
So it seems like there is a bit of inertia with implementations to follow a
fifteen years old specification update. This warrants a look at the major
implementations.
Scroll down for the summary table.
Server implementations
According to the s.j.n stats,
the top 5 server implementations on the federated XMPP network are
Prosody (60%), ejabberd (24%),
Spectrum (6%),
biboumi (4%) and "Multi User Chat" (1%). And
while biboumi is the only one without its own .IM domain, we can still exclude
it and Spectrum from the list, as they are bridges to other networks and need
to adhere to the limitations of those networks. "Multi User Chat" is in fact
the MUC component of the Tigase
server.
A cross-match with the servers connected to
yax.im also yields similar results, and adds
Openfire as a candidate
with 1.5% market share.
prosody
Lua
isn't exactly friends with Unicode,
so prosody went for a manual approach and implemented Stringprep in
encodings.c
using either ICU or
libidn, based on a compile-time switch.
The binary packages built by the prosody team use ICU, so we'll take that for
the comparison.
libICU
ICU (International Components for Unicode) has a very turbulent history -
initiated at a spin-off from Apple and IBM, and written in Java, the first
version got integrated into the Java SDK in 1997, then developed in parallel
and ported from Java to C++ and C. prosody is using the C version. ICU
supports IDNA2008, which prosody
started using in 2019. However, ICU
only supports Stringprep,
not PRECIS (probably due
to the fact that Stringprep was a required part of IDNA2003).
libidn and libidn2
libidn on the other hand
started out as libstringprep,
and supports IDNA2003 and Stringprep.
libidn2 was created to support IDNA2008,
but it removed Stringprep support,
so can't be used as a drop-in replacement.
You have the choice between IDNA2003 with Stringprep and IDNA2008 without
PRECIS.
ejabberd
ejabberd is written in Erlang, a language that's as
powerful as it is obscure. The ejabberd developers have implemented their own
stringprep library and use
erlang-idna which supports both
IDNA2003 and IDNA2008, but haven't tackled PRECIS.
Tigase
Tigase is written in Java and seems to have
forked and heavily reformatted
the December 2004 libidn 0.5.12
release. There is no mention of IDNA2008, nor of PRECIS in the source, so I
would assume IDNA2003 and Stringprep.
Openfire
Openfire uses Tinder for the XMPP
stanzas, and that makes use of
libidn 1.35.
As this is not libidn2, Openfire is at IDNA2003 and Stringprep. But there is
an abandoned half-finished PR to implement PRECIS!
Client implementations
According to the JabberFR client stats, the top
5 client implementations are:
- Conversations
- Cheogram (a Conversations fork)
- Monocles (a Conversations fork)
- Gajim
- Monal
- Pidgin
- Blabber.im (an abandoned Conversations fork)
- Dino
Conversations
Conversations is a modern Android client that's making use of
jxmpp-stringprep-libidn,
which is using
libidn 1.15
which gives us IDNA2003 and Stringprep.
Gajim
Gajim was in fact the client that told me that
I'm holding it wrong and
that made me write this blog post.
Gajim is using nbxmpp and nbxmpp is using
precis-i18n, which implements the
trifecta of 8264, 8265, and 8266! In
addition, idna is used for full IDNA2008
support.
So far, Gajim is the only client that will allow Unicode >3.2 emoji in
nicknames (and nowhere else)!
Monal
The authentication code is doing
manual stringprep,
but other than that there is no support for Stringprep or PRECIS. IDNA2008 is
handled by the underlying iOS core library.
Pidgin
Pidgin. My nemesis. The formerly most-widely used XMPP client that made a
generation of users believe that XMPP is stuck in 2004. Pidgin is using
libpurple, which was
famously called
"a flock a zero days flying in formation"
a decade ago.
A 2009 patch
implemented IDNA2003 and Stringprep support based on libidn, and it seems to
have survived in the 2.14 "stable" branch, which was last released in January
2025.
The 3.0 development branch does not contain any traces of IDNA, Stringprep or
PRECIS.
Dino
Dino, a modern client written in Vala, uses a binding to
libICU, but without the UIDNA_USE_STD3_RULES flag that would enable
IDNA2008.
Implementation overview
The analysis of the client and server implementations shows that most
implementations lag behind by a decade. There are two notable exceptions:
Gajim implements the current state-of-the-art, and Monal allows everything and
lets the server sort things out.
| Implementation |
username |
hostname |
nicknames |
| Servers |
| prosody |
👆️ Stringprep |
❌ IDNA2008 |
👆️ Stringprep |
| ejabberd |
👆️ Stringprep |
❌ IDNA2008 |
👆️ Stringprep |
| Tigase |
👆️ Stringprep |
👆️ IDNA2003 |
👆️ Stringprep |
| Openfire |
👆️ Stringprep |
👆️ IDNA2003 |
👆️ Stringprep |
| Clients |
| Conversations |
👆️ Stringprep |
👆️ IDNA2003 |
👆️ Stringprep |
| Gajim |
❌ PRECIS |
❌ IDNA2008 |
🤖 PRECIS |
| Monal |
🤖 anything goes |
❌ IDNA2008 |
🤖 anything goes |
| Pidgin |
👆️ Stringprep |
👆️ IDNA2003 |
👆️ Stringprep |
| Dino |
👆️ Stringprep |
👆️ IDNA2003 |
👆️ Stringprep |
❌ = not allowed | 👆️ = legacy Unicode 3.2 | 🤖 = modern Unicode
Summary / TL;DR
The original XMPP specification (2004-2010; IDNA2003 + Stringprep) didn't
forbid Emojis in any parts of an XMPP address, but was limited to Unicode 3.2,
which only had around 150 Emojis. xmpp:👆️@♻️.❤️/⁉️
When IDNA2003 was replaced by IDNA2008 in 2010, hostnames were restricted to
characters from actual human languages. The two most widely deployed server
implementations enforce this limit, but might support pre-existing legacy
hostnames. xmpp:☹️@𓀐.𓂸/☢️
When the XMPP specification implemented PRECIS in 2017, usernames were also
limited to human languages, but the resource / nickname part was left
permissive, and opened up to all existing and future Unicode specifications.
xmpp:𓀬@ツ.ۃ/🤖
So after going through 22 years of development, 19 RFCs and 17 Unicode
standards, I have to say: the internet was
right and I was wrong.
👆️.op-co.de is not a valid JID, but it was unti 2010.
Discuss on Mastodon